Latent dirichlet allocation based diversified retrieval for e-commerce search
概要
ECサイトの検索に,商品のタイトルの中の単語の出現分布を多変量ベルヌーイ分布でモデル化したLatent Dirichilet Allocation(LDA)を組み込んだ論文.第一著者のeBayでのインターンの成果.
例えばECサイトで”Fossil”というクエリをユーザが投げたときに,ユーザはブランドとしての”Fossil”の時計やバッグが欲しいかもしれないし,単に化石のアンティークが欲しいかもしれない.ユーザの興味に関する情報が無いときには,曖昧なクエリに対してなるべく多様な種類の商品を検索結果として返したい.単純にクエリに対応する商品が複数のカテゴリにまたがる場合は,カテゴリごとに商品を表示するという方法が簡単なのだけれども,カテゴリによって粒度が異なるのでうまくいく場合といかない場合がある.そこで,商品のタイトルを使ったトピックモデルを考えてカテゴリの代わりにしたい.ただしタイトルはそもそも単語の数が限られていて出てくる種類も少ないので,単語の出現分布をベルヌーイ分布でモデル化したLDAを考える.
背景
上の”Fossil”の例のように検索クエリには冗長性があるので,提示する検索結果には複数のカテゴリのものを提示してユーザの意図を汲み取る必要がある.しかも,通常のウェブ検索とは違ってユーザが商品を出品するようなECサイトでは,似通った商品が大量に存在しやすく,それぞれの商品の情報をユーザが好きに記述することができるなど,IR的な方法では対処が難しい.一つの方法として,商品に付けられたカテゴリの情報を使う方法が考えられるが,決まった粒度でしっかり付けられているわけではないので扱いにくい.例えば,これは結果の方にも出てくるのだけれども,iPod touchやiPod nano,iPod classicは同じカテゴリに含まれているため,”iPod”というクエリのケースでは,粒度が粗くてカテゴリを元に異なるタイプの商品を提示できない.
手法
そこで,この論文ではクエリだけでは分からない隠れたユーザの意図を元にして多様な商品を検索結果として提示するために,LDAを用いる.それには以下の3段階で行う.
- クエリからユーザの意図を汲み取る(Discovering user intents)
- ユーザの意図をランク付けする(Ranking user intents)
- ユーザの意図から商品を選択する(Selecting items for user intents)
1. Discovering user intents
文章分類などに用いられるLDAはトピックに関連する特定の単語が何度も出てくるということを想定しているが,今回対象としているECサイト上の商品のタイトルは,大抵が短いものでしかも同じ単語が重複して出てくることは無い.そこで,LDAによく用いられる多項分布に変わって,多変量ベルヌーイ分布を用いたMultivariate Bernoulli LDA(MB-LDA)を考える.グラフィカルモデルはFigure 2のような感じ.推論は通常のLDAと同じようにギプスサンプリングで行える.
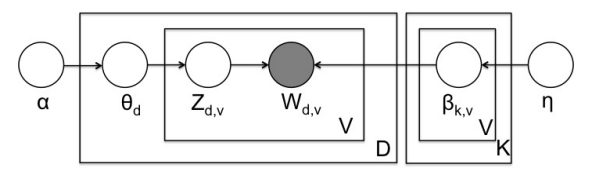 (Figure 2:WSDM2014.pdf)
(Figure 2:WSDM2014.pdf)
2. Ranking user intents
クエリからMB-LDAで推測したユーザの意図をもとに,relevanceとinformation noveltyのトレードオフを考慮してランク付けする.ここでrelevanceはユーザの意図の重要度,information noveltyは追加情報の量を表す.それぞれの比率を$\lambda$と$1-\lambda$として足し合わせたものを考える.
3. Selecting items for user intents
最後に,もっともユーザの意図を反映した商品を選択する.ユーザの意図自体はMB-LDAで特徴付けられているので,そこで推定したパラメータ$\beta_{k,W_{i,j}}$を重みとして利用しつつスコアを算出する.ただし,スコアは商品タイトルの長さによって正規化する.
評価指標
検索結果の評価に良く使われる適合率や再現率,NDCGは商品間の関連を表現できないほか,他の指標も人間の主観的な判断などを使うので,評価指標としてこの研究には使えない.今回は新しい指標Average Satisfaction(AS)を提案している.
実験
eBayのデータを使って実験.対象とするクエリは,2週間の間にeBayで検索されたクエリ全体の中から120個をランダムで選択した.選んだクエリはだいたい1日に300回から30,000回ほど検索されるもので,ほとんど検索されないレアなものはそもそも除外している.それぞれのクエリについて,2ヶ月の間ユーザのクリックデータを収集した.LDAに使用するbag-of-wordsは,商品のタイトルの単語以外にも,カテゴリの名前を”cat-“を接頭辞に付けて単語として加えた.
評価には,既存手法を含めて全部で6つの方法を使用.現在使用しているeBayの検索アルゴリズム,MMR,PLMMR,カテゴリベースの手法(Cat),LDA,そして今回提案しているMB-LDA.それぞれの詳細は論文参照.
結果
まずLDAがクエリからユーザの興味を見つけられているかを確かめるために,fossil,basketball,iPodの3つのクエリに対してトピック数5のMD-LDAで実験した結果がTable 1.ここでは出現確率が高かった単語を右に,人間が見てそのトピックに対応しそうな名前を左に示している.これを見るとカテゴリの違いをおおよそ認識できているし,iPodというおおまかなクエリからiPod touchやiPod nanoなどの違う製品を異なるトピックに分類できていることがわかる.
次に現在のeBayの検索アルゴリズムとの比較を,検索結果トップ10件までの検索結果に対するASの差についてプロットした図がFigure 2.一番良かったのがLDAとMB-LDA,次にカテゴリベースのCat,そしてMMRとPLMMRという結果になった.LDA2つとCatについては検索結果10件すべて有意に差があった.一方でMMRとPLMMRがうまく行かなかった理由としては,MMRはそもそもユーザの隠れた興味を反映できなく,PLMMRはそれを反映できたものの商品のタイトルの長さを考慮していなくて,すごい短いかすごい長いタイトルを選びがちだったと考えられる.Catはクエリのあいまいさ(ambiguity score)が低いクエリに関しては性能が下がったが,MB-LDAはあいまいさに関係無く高いスコアを示した(Figure 4).そんなMB-LDAでも”lego”のように商品のタイトルが付ける人によってバラバラで情報量が少ない場合には,カテゴリベースの手法の方が上手くいく結果となった.
他の手法との比較で一番分かりやすい結果がTable 4.これを見ると,”fossil”というクエリに対して,現在のeBayの検索アルゴリズムの結果がカバンだけなのに対し,カテゴリベースではカバンと時計の2種類,提案手法のMB-LDAではカバンと時計と歯の化石の3種類が提示された.このことからも,LDAを利用した手法は検索結果の商品の種類が多様になりやすいことがわかる.
 (Table 4:WSDM2014.pdf)
(Table 4:WSDM2014.pdf)
あと,トピック数を変えたときの結果の違いがFigure 5に示されている.ここではトピック数K=10とK=20で実験しており,ランキング上位のみではトピック数が少ないK=10の方が性能がいいものの,ランキング下位まで含めるほどにトピック数が多いK=20の方が良くなる.検索結果として表示できる商品数が多いならいろんな商品を出したほうが結果は良くなりやすい.表示数に応じてトピック数を変えれば良さそうという結論.
感想
論文中のRelated Workでも述べられている通り,検索結果の多様化というところでは既存研究もかなりあるようだ.それを踏まえてこの論文ではeBayというユーザ出品型のECサイトでの問題点をきちんと定義して,実問題に合わせるようにLDAを拡張して問題を解いていて明解な研究だと思う.
ちなみに,現在ebay.comのトップページで”fossil”と検索してもブランドの時計とバッグしか出てこない模様……実用化はまだ難しいのかもしれない.プロダクトに組み込むとなると,検索速度などの実装面やカテゴリを選択した上での検索はどうするかなど,考慮しなければいけない要素は多い.ただし,Figure 1に示されているようにユーザが自分で意図する商品の種類を選択することも原理上可能で,検索クエリを投げるユーザ自体の情報を使うこともできそうというところで,色々と応用や改善ができそうではある.
参考
- web.engr.oregonstate.edu/~wong/papers/pdf/WSDM2014.pdf
- Latent Dirichlet Allocations(LDA) の実装について - Mi manca qualche giovedi`?
- トピックモデル関係の論文メモ - tsubosakaの日記

コロナ社
売り上げランキング: 20,114