puyokwさんの記事に触発されて,私もPythonでXgboost使う人のための導入記事的なものを書きます.ちなみに,xgboost のパラメータ - puyokwの日記にはだいぶお世話になりました.ありがとうございました.
Xgboostとは
Xgboostは言わずと知れた最近流行りのGradient Boosting系のライブラリで,独立したバイナリとしてコマンドラインから実行できるほか,RやPythonからもライブラリとして利用することができる.詳しくい情報は以下の記事を参照していただきたい.
- 勾配ブースティングについてざっくりと説明する - About connecting the dots.
- xgboostとgbmのパラメータ対応一覧をつくる - 盆栽日記
- 最近、流行のxgboost - puyokwの日記
はじめの一歩
XgboostのドキュメントPython Package Introductionに基本的な使い方が書かれていて,それはそれでいいんだけれども,もしscikit-learnに馴染みがある人ならデモの中にあるsklearn_examples.pyを見て使い方を学んだほうが良いだろう.
XgboostのPythonラッパーはわりとscikit-learnの文法に沿って書かれているので,Python環境においても比較的親和性が高い.scikit-learnでよく利用するRandom ForestやGBRTのモデルで定番のmodel作ってfitしてpredictして……と同じように,Xgboostでも似たコードを書けばとりあえずは動かすことができる.XgboostにはXGBClassifierとXGBRegressorがあるので,最初にどちらを使うか選択して,あとは以下のようなカタチで書くことができる.
xgb_model = xgb.XGBClassifier()
xgb_model.fit(X_train, y_train)
predict = xgb_model.predict(X_test)
デモ:irisの多クラス分類
今回はpuyokwさんの記事のサンプルコードを少しお借りして,irisの多クラス分類をxgboostで,なおかつscikit-learnっぽく書いてみる.全体のコードは以下のリンク先のgistに上げておいたので,そちらも参照していただきたい.
GridSearchCVを使った10-fold CV
さて,いきなりだがクロスバリデーション(CV)をどうしようかと考えてみる.xgb.cvを使ってスコアを出しつつ計算してもいいのだけれど,パラメータチューニングのことも考えるとscikit-learnのGridSearchCVを使うのが一番手っ取り早い.グリッドサーチはもともと列挙したパラメータのパターンすべてを試行する方法だが,xgbのパラメータをそれぞれ1つだけ指定しておけばパラメータ決め打ちで実行しているのと変わらない.実際にはCVのfoldやスコア算出の方法を指定するだけで良いので,train_test_splitやKFoldなどのデータ分割の方法自体を考えずに済むので便利だ.
# Grid Search
params={'max_depth': [5],
'subsample': [0.95],
'colsample_bytree': [1.0]
}
xgb_model = xgb.XGBClassifier()
gs = GridSearchCV(xgb_model,
params,
cv=10,
scoring="log_loss",
n_jobs=1,
verbose=2)
gs.fit(trainX,trainY)
predict = gs.predict(testX)
print confusion_matrix(testY, predict)
実行すると以下のような出力が得られる.今回の場合verbose=2にしているので大量の情報が出ているが,デフォルトのverbose=0だと最後のconfusion matrix以外は何も出力されない.
Fitting 10 folds for each of 1 candidates, totalling 10 fits
[CV] subsample=0.95, colsample_bytree=1.0, max_depth=5 ...............
[CV] ...... subsample=0.95, colsample_bytree=1.0, max_depth=5 - 0.0s
[Parallel(n_jobs=1)]: Done 1 jobs | elapsed: 0.0s
[CV] subsample=0.95, colsample_bytree=1.0, max_depth=5 ...............
[CV] ...... subsample=0.95, colsample_bytree=1.0, max_depth=5 - 0.0s
[CV] subsample=0.95, colsample_bytree=1.0, max_depth=5 ...............
[CV] ...... subsample=0.95, colsample_bytree=1.0, max_depth=5 - 0.0s
[CV] subsample=0.95, colsample_bytree=1.0, max_depth=5 ...............
[CV] ...... subsample=0.95, colsample_bytree=1.0, max_depth=5 - 0.0s
[CV] subsample=0.95, colsample_bytree=1.0, max_depth=5 ...............
[CV] ...... subsample=0.95, colsample_bytree=1.0, max_depth=5 - 0.0s
[CV] subsample=0.95, colsample_bytree=1.0, max_depth=5 ...............
[CV] ...... subsample=0.95, colsample_bytree=1.0, max_depth=5 - 0.0s
[CV] subsample=0.95, colsample_bytree=1.0, max_depth=5 ...............
[CV] ...... subsample=0.95, colsample_bytree=1.0, max_depth=5 - 0.0s
[CV] subsample=0.95, colsample_bytree=1.0, max_depth=5 ...............
[CV] ...... subsample=0.95, colsample_bytree=1.0, max_depth=5 - 0.0s
[CV] subsample=0.95, colsample_bytree=1.0, max_depth=5 ...............
[CV] ...... subsample=0.95, colsample_bytree=1.0, max_depth=5 - 0.0s
[CV] subsample=0.95, colsample_bytree=1.0, max_depth=5 ...............
[CV] ...... subsample=0.95, colsample_bytree=1.0, max_depth=5 - 0.0s
[Parallel(n_jobs=1)]: Done 10 out of 10 | elapsed: 0.1s finished
[[25 0 0]
[ 0 23 2]
[ 0 0 25]]
なお,gs.best_estimator_やgs.best_score_から最も良かったモデルやスコアが取得できるほか,グリッドサーチで計算された個々のフィッティング結果も同様に取得することができる(今回は1回しか実行していないので意味は無いが).
In [6]: gs.best_estimator_
Out[6]:
XGBClassifier(base_score=0.5, colsample_bytree=1.0, gamma=0,
learning_rate=0.1, max_delta_step=0, max_depth=5,
min_child_weight=1, missing=None, n_estimators=100, nthread=-1,
objective='multi:softprob', seed=0, silent=True, subsample=0.95)
In [7]: gs.best_score_
Out[7]: -0.11739138306428988
In [8]: gs.grid_scores_
Out[8]: [mean: -0.11739, std: 0.13540, params: {'subsample': 0.95, 'colsample_bytree': 1.0, 'max_depth': 5}]
RandomizedSearchCVを使ったチューニング
せっかくGridSearchCVの説明をしたので,RandomizedSearchCVの話もついでに書いておこう.
Xgboostを使うときにはパラメータ決め打ちで実行するなんてことは実際にはほとんどなく,パラメータチューニングによって最適なパラメータを探す必要がある.グリッドサーチは有効かつ確実な手段だが,実際には複数あるパラメータの値を微妙に変化させて細かく探索するには時間がかかりすぎる.最初に大まかに探索して当たりを付けて,有望な値付近で細かくグリッドサーチするのが常套手段ではあるが,すべてのパラメータの値をこちらで指定して実行を繰り返す人力チューニングは割と面倒ではある.
もしおおまかに探索してみて,このパラメータは小さい値を取りやすいとか,どの値の近辺に山があるかといった何らかの事前情報があれば,それにしたがってランダムに探索すれば効率的かもねというのがランダムサーチの大雑把な考え方になる.例えば,SVMのパラメータは指数増加列で探すのが良いという話がある(SVM実践ガイド (A Practical Guide to Support Vector Classification) - 睡眠不足?!).グリッドサーチなら$C=2^{-5},2^{-4}\dots$のように値を決め打ちで指定するが,ランダムサーチではパラメータに指数分布などの何らかの分布を仮定し,そこからランダムで値を取ってきて試すというのを繰り返すことになる.直感的に理解するならば,Bengio先生の以下の図が分かりやすいだろう.
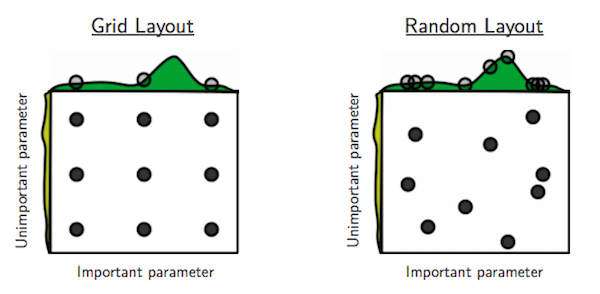 (bergstra12a.pdfより)
(bergstra12a.pdfより)
グリッドサーチの網目から漏れてしまう部分を拾えたり,重要なパラメータとそうでないパラメータで探索の分布や幅などを変えるといった柔軟な対応が,ランダムサーチでは可能になる.まあ実際にはある程度試行回数を増やさないとそもそも見つけられなかったりもするのだけれども,逆に言えばランダムサーチはその試行回数さえ決めておけば適当に探しておいてくれるというのがコードを書く上では地味に便利になる.実装上グリッドサーチは,指定したパラメータのパターン全部を計算しないと次にいけない.試行錯誤を繰り返すときに逐一パラメータの候補を自分で選別してトータルの試行回数を調節するのは果てしなく面倒で,パラメータチューニングを上手くサボるのには向いていないということだ.その点ランダムサーチはこの範囲の中で適当に10回くらい,または念入りに1000回くらい細かく,という探索ができるので,手軽にパラメーターの探索を加減することができる.
さらにこれをもっと進化させて,先ほどグリッドサーチの箇所で説明した大まかなチューニングから細かなチューニングをランダムサーチでといった話になると,今度はベイズ的最適化(bayesian optimization)のような話になってくる.Pythonではhyperoptやspearmint,今はTwitterに買収されてしまったWhetlabなど最近は色々と出てきているが,今回は割愛する.
だいぶ横道にそれてしまったが,ランダムサーチの実際のコードを見てみよう.以下の例では,max_depthは1から10までのrandint,subsampleとcolsample_bytreeは$[0.5, 1]$の一様分布を仮定して,そこからランダムに値を取り出してくるという試行をRandomizedSearchCVのn_iterで指定した回数行う.それぞれにcvで指定したn-fold CVが走るので,今回の場合内部では200回xgboostが走ることになる.
param_distributions={'max_depth': sp.stats.randint(1,11),
'subsample': sp.stats.uniform(0.5,0.5),
'colsample_bytree': sp.stats.uniform(0.5,0.5)
}
xgb_model = xgb.XGBClassifier()
rs = RandomizedSearchCV(xgb_model,
param_distributions,
cv=10,
n_iter=20,
scoring="log_loss",
n_jobs=1,
verbose=2)
rs.fit(trainX,trainY)
predict = rs.predict(testX)
まとめ
以上のように,Pythonでもxgboostとscikit-learnを組み合わせれば,わりと簡単に使いこなすことができる.Pythonの強みであるscikit-learnやpandasなどの豊富な機能を組み合わせて解析することができるのは大きな利点であり,とりあえず回帰したい分類したいといったときの選択肢の一つとなりうるだろう.どうやら最近Pythonの方にもEarly-stoppingの機能が追加されたりと(link),まだまだ開発は続いているので,遠くない将来Rと同等の機能がPythonでも実現されるかもしれない.Xgboost使いたいけどPythonの方は日本語の記事少ないしなんか機能的にRの方がいいのかなぁ……と乗り気でなかった人は,ぜひともこの記事や公式のサンプルコードを参考にPythonで使ってみてもらえればと思う.
補足:Xgboostの使用するCPUコア数には気を付ける
誰もがハマるであろう落とし穴があるので補足.
xgb.XGBClassifier()やxgb.XGBRegressor()はデフォルトでnthread=-1となっており,CPUのコアをすべて使用する設定となっている.一方でGridSearchCVやRandomizedSearchCVにも同様に,n_jobsという実行するときのコア数を指定するパラメータがある.どちらも-1にしているとCPUコア数の二乗相当の計算が走ってしまい,load averageがとんでもないことになるので注意.GridSearchCVやRandomizedSearchCV はn_jobs=1にしておくのが無難だろう.
In [2]: xgb.XGBClassifier()
Out[2]:
XGBClassifier(base_score=0.5, colsample_bytree=1, gamma=0, learning_rate=0.1,
max_delta_step=0, max_depth=3, min_child_weight=1, missing=None,
n_estimators=100, nthread=-1, objective='binary:logistic', seed=0,
silent=True, subsample=1)