概要
情報抽出(Information Extraction:IE)のサーベイ論文.情報抽出にはルールベースの手法と機械学習ベースの手法の2種類があるが,アカデミアとビジネスでそれらの使われ方であったり認識に大きな乖離がある.アカデミアではルールベースはもはや見込みの無い技術だと思われがちだけれども,むしろビジネスの実務ではルールベースの方が成果面・コスト面で重要であって,そこの活用が両者の溝を埋める可能性があるという話.
内容
 (Figure 1: D13-1079.pdf)
(Figure 1: D13-1079.pdf)
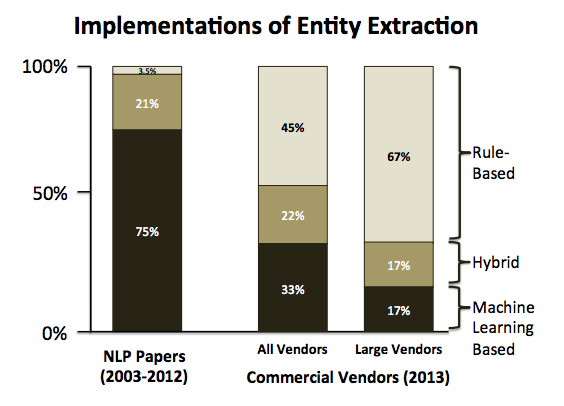
情報抽出の手法のサーベイ.アカデミアにおいては,EMNLP,ACL,NAACLの2003年から2012年までに出版されたEntity Extraction関連の全論文177本の手法を,それぞれルールベースの手法,機械学習の手法,どちらも使用したハイブリッドな手法の3つに分類した.その結果,純粋なルールベースの論文は6本しかなく,それ以外は機械学習を利用したものだった.ハイブリッドな手法においても,ルールベースも利用するとは名言せず,”dependency restrictions”や”entity type constraints”,”seed dictionaries”といった婉曲表現を使うケースがあった.
一方で,ビジネスにおける情報抽出のシステムに関しても合計41のプロダクトにおいて同様に集計した結果,大多数のベンダーがルールベースの手法を採用し,機械学習の手法を採用しているのは1/3程度しかなかった.その中でも特に主要なベンダーであるIBMやSAP,Microsoftは完全にルールベースを採用していた.ここで挙げられているベンダーのプロダクト一覧は論文を参照.
以上のサーベイの結果より,アカデミアで培った最先端の技術をビジネスに流用しているという流れは主流ではなく,両者の間にはギャップが存在している.
かと言ってお互い交流が無いというわけではなく,それぞれの手法の成果やコストに関するPros/Consが影響していると考えられる.詳しくは論文Table 2および本文参照.
これらのお互いの理由を踏まえて,アカデミアはルールベースの手法を時代遅れだと考えるのを辞めるべきで,ルールベースの中でもまだ手の付けられていない部分が残っている.それらを踏まえると,研究者は以下の研究にフォーカスすべきであるという.
(a) data models and rule language
(b) system research in rule evaluation
(c) machine learning research for learning problems in the richer target language
つまり,情報抽出のタスクには標準仕様(IE rule language)が必要であり,それはSQLのようなものであるという.SQLは実務でも広く使われると同時に,データマネージメント分野でも盛んに研究されている.そういった点を倣い,情報抽出のタスクにおいてもまずはIE rule languageを策定するべきである.実際に近年データベースのコミュニティでは,AQLやSQLのエクステンションといった形でルールベースの情報抽出のシステムが登場しているらしい.
個人的な感想
まさか情報抽出のサーベイからSQL的な言語が必要みたいな話に至るとは思わなかった.最後まで読むと論文のタイトルの意味がようやく分かる.あまり想像はつかないけれども,産学で溝を埋めていくにはタイトルにあるようにシステムとして作らなければならず,標準化なりの仕組みを整えて足並みを揃えていく方向性も必要なのかもしれない.もちろんアカデミアも論文が採択されるには,ルールベースでstate-of-the-art出ましたといっても受けが悪いだろうし,結局は凝った機械学習の手法をしないと見向きもされないみたいな傾向がありそうだ.実務と研究を両立するという意味での仕様策定という仕組み作りは,わりと面白いかもしれない.