Searching Satellite Images with Text — A Vision Language Model Approach
Table of Contents
This article was automatically translated from Japanese by AI.
Overview
In the previous article, I tried a Query-by-Example search using AlphaEarth Satellite Embeddings to find “similar structures.” Since the approach involved selecting a rectangle on a map and using approximate nearest neighbor search (ANN) to find similar locations, it was not possible to directly express intentions like “find airports” or “find golf courses.”
This time, I’ll try building a system that searches satellite images directly using natural language text queries. Using RemoteCLIP, a VLM (Vision-Language Model) fine-tuned for remote sensing imagery, I can search for matching satellite image tiles simply by entering text like "airport" or "golf course".
What is RemoteCLIP?
RemoteCLIP (Liu et al., 2024) is a model that fine-tunes OpenAI’s CLIP on approximately 800,000 remote sensing image-text pairs. Since CLIP can embed both images and text into the same vector space, we can split satellite images into tiles, pre-generate embeddings, and then embed text queries into the same space for similarity search via ANN, enabling text-to-image retrieval.
Implementation
The source code for the implementation described in this article is available on GitHub.
Satellite image natural language search system using VLM embeddings
The overall processing flow is as follows, divided into two parts: index construction and natural language search.
[Index Construction]
Download from Sentinel-2 (STAC API)
↓
Tile splitting
↓
Embedding generation with RemoteCLIP
↓
Index construction with Qdrant
[Natural Language Search]
Text query
↓
Text embedding with RemoteCLIP
↓
Similarity search with Qdrant
↓
Display results
Data Source
I used Sentinel-2 L2A for satellite imagery. Sentinel-2 is an Earth observation satellite operated by ESA (European Space Agency), and its data is freely available to anyone. L2A is an atmospherically corrected surface reflectance product with a spatial resolution of 10m for visible light bands. I acquired RGB 3 bands, clipped the reflectance values (uint16) to a range of 0-3000, then converted them to uint8 in the 0-255 range.
For this experiment, I targeted the Kanto Plain, acquiring images from April to June (spring) with cloud cover below 20% to ensure ground structures were visible.
Index Construction
Scene Acquisition and Tile Splitting
I acquired Sentinel-2 scenes through Element84’s STAC API and saved them locally as GeoTIFF files. Then I split them into 224×224 pixel tiles matching RemoteCLIP’s input size. Since Sentinel-2’s resolution is 10m/pixel, each tile corresponds to approximately 2.24km × 2.24km of ground surface.
When splitting tiles without overlap, structures straddling tile boundaries would only partially appear in either tile and could be missed during search. To address this, I set the stride to half the tile size (112 pixels), creating 50% overlap between adjacent tiles so that structures fall near the center of at least one tile.
As a result, the number of tiles for the Kanto Plain was 788 without stride and 3,133 with 50% stride.
Embedding Vector Generation
I fed the split tile images into RemoteCLIP to generate embeddings. I tried two models: ViT-B/32 (512 dimensions) and ViT-L/14 (768 dimensions). Inference was performed on GPU (CUDA) with FP16 at a batch size of 64.
Vector Index Construction
I used Qdrant as the vector database for making the generated embeddings searchable. In the previous article, I used Faiss, but Faiss specializes in pure ANN search and lacks built-in metadata filtering or REST API. Qdrant is lightweight and built in Rust, supporting metadata filtering through payloads as well as native geospatial filtering such as bounding box and radius searches. For satellite image search, spatial constraints like “search within a specific region” are necessary, so the ability to combine vector similarity search and spatial filtering in a single query is a significant advantage. I used it in local file storage mode, storing latitude/longitude, scene ID, region, and other metadata as payloads.

Natural Language Search
During natural language search, the input text is converted to embeddings using RemoteCLIP’s text encoder, and the top-k results are returned based on cosine similarity with tile image embeddings in Qdrant.
For the interface, I built the backend with FastAPI and the frontend with React + TypeScript + MapLibre GL JS to display search results on a map.
Heatmap Visualization with ClearCLIP
I generated heatmaps to visualize which regions of the image the model focuses on for search results. I adopted ClearCLIP (Lan et al., ECCV 2024) as the method.
In ClearCLIP, the residual connection and FFN are skipped in the final Transformer block of the ViT encoder, extracting only the self-attention output to obtain local features corresponding to each patch. The mean across all patches is then subtracted to remove common components. The resulting patch features (16×16=256 patches, each 768-dimensional for ViT-L/14) are compared with the search text embedding using cosine similarity, reshaped into a spatial grid, and overlaid on the original image to generate the heatmap.
Search Examples
I tested several text queries against satellite imagery of the Kanto Plain.
In the screenshots below, the left side shows the search query and various conditions including the model used, the center shows a map with dots indicating hit locations, and the right side displays satellite images of hit locations in descending order of similarity along with ClearCLIP heatmaps within those regions.
“airport”
The results for airports were good. In addition to Haneda Airport, runways at Self-Defense Force and US military bases were also retrieved.
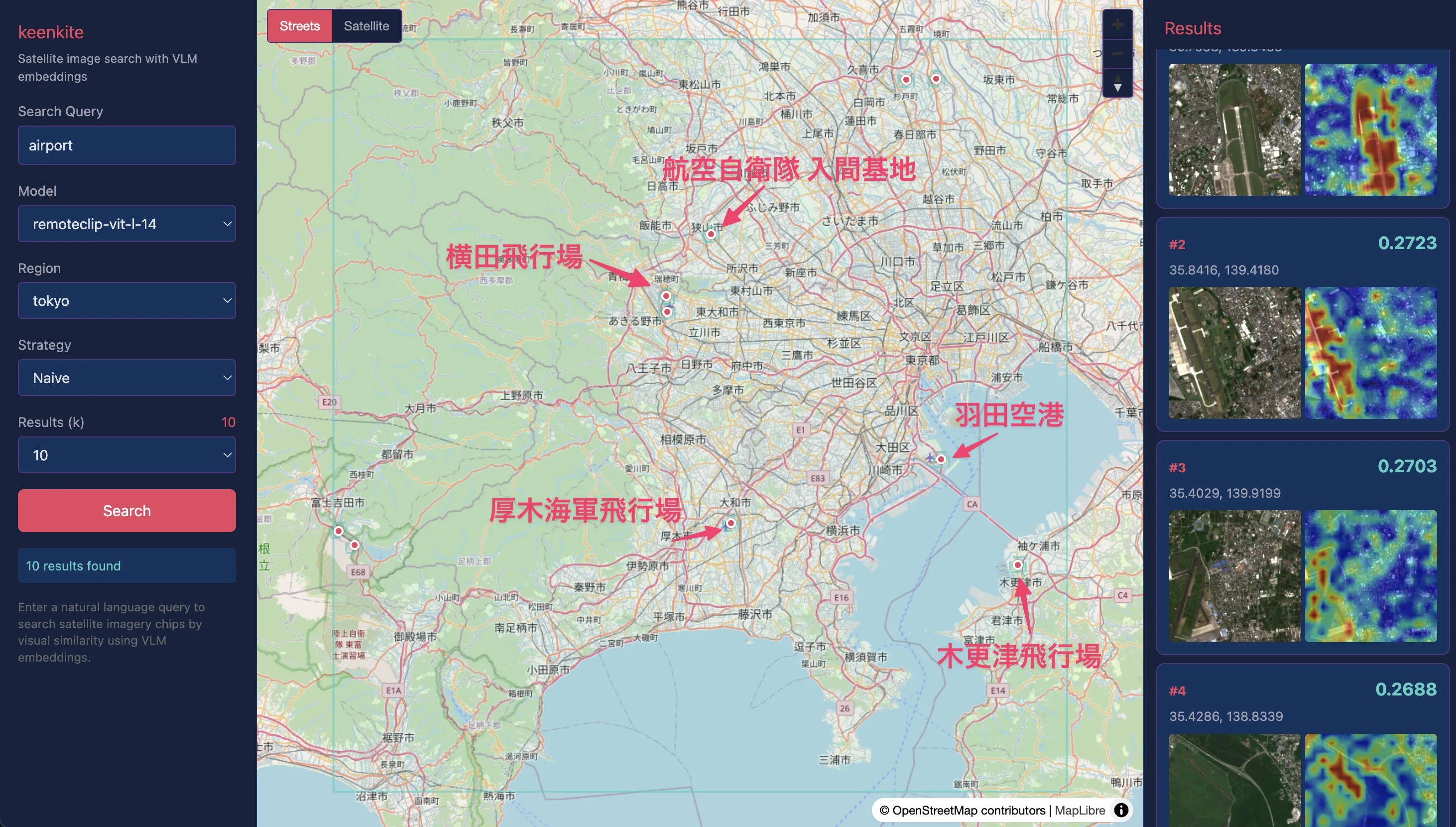
As shown below, the ClearCLIP heatmap also confirms that runway areas show high similarity with the query. Some false positives in highway sections near Yamanashi Prefecture suggest that runways, rather than airport terminals, are the primary identification cues.
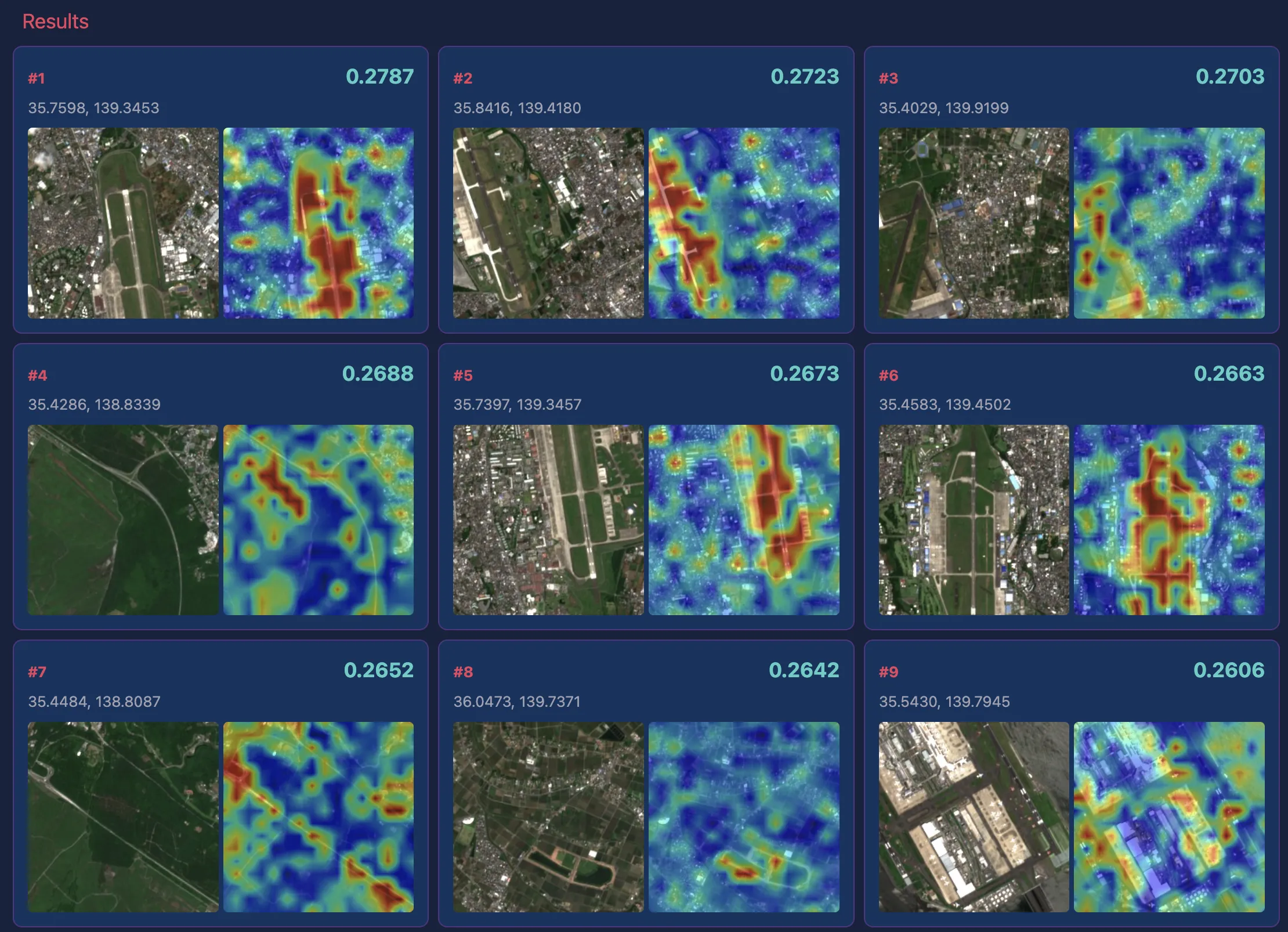
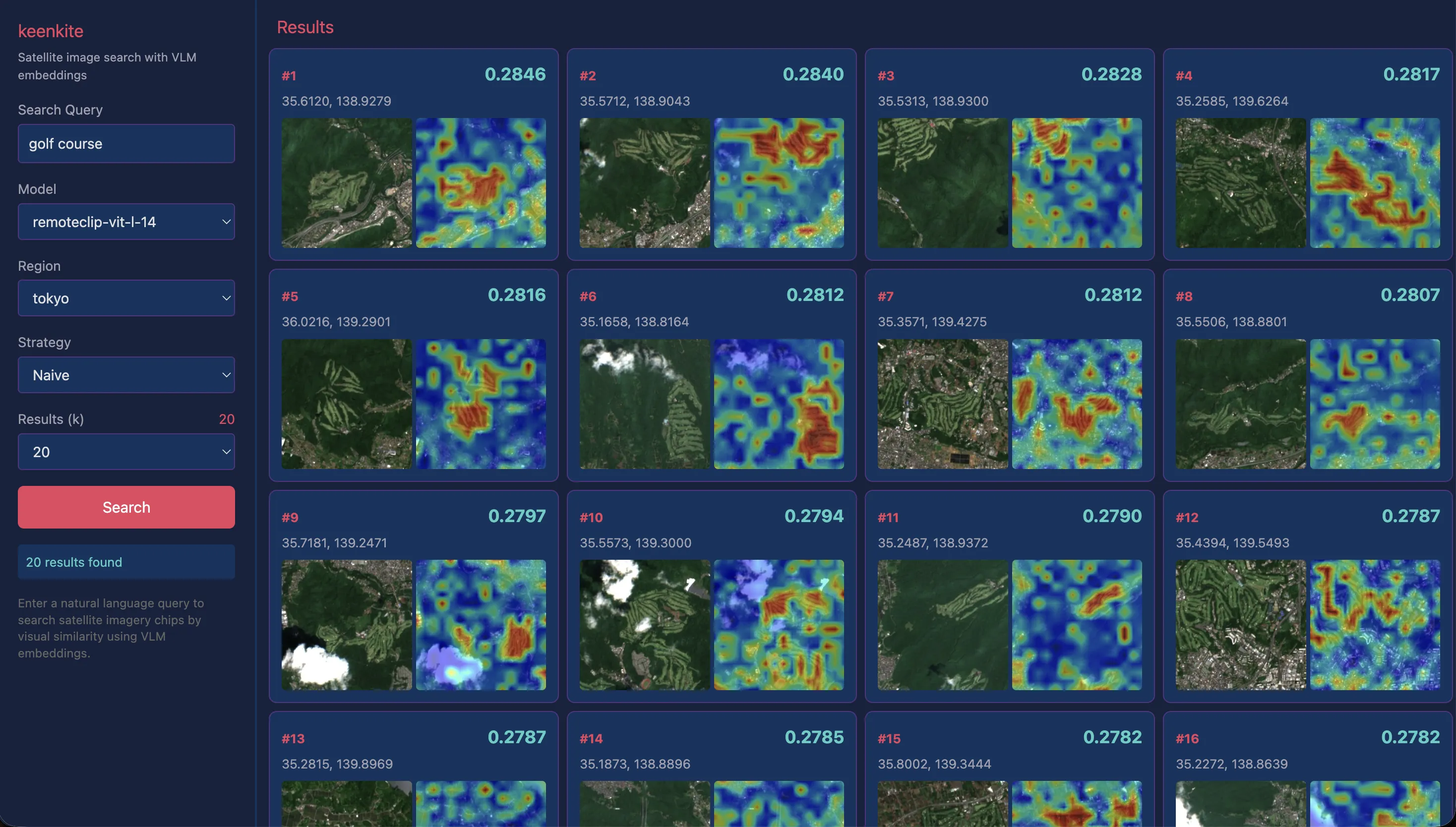
“golf course”
Golf courses were accurately captured in almost all examples, as confirmed by both satellite images and heatmaps.
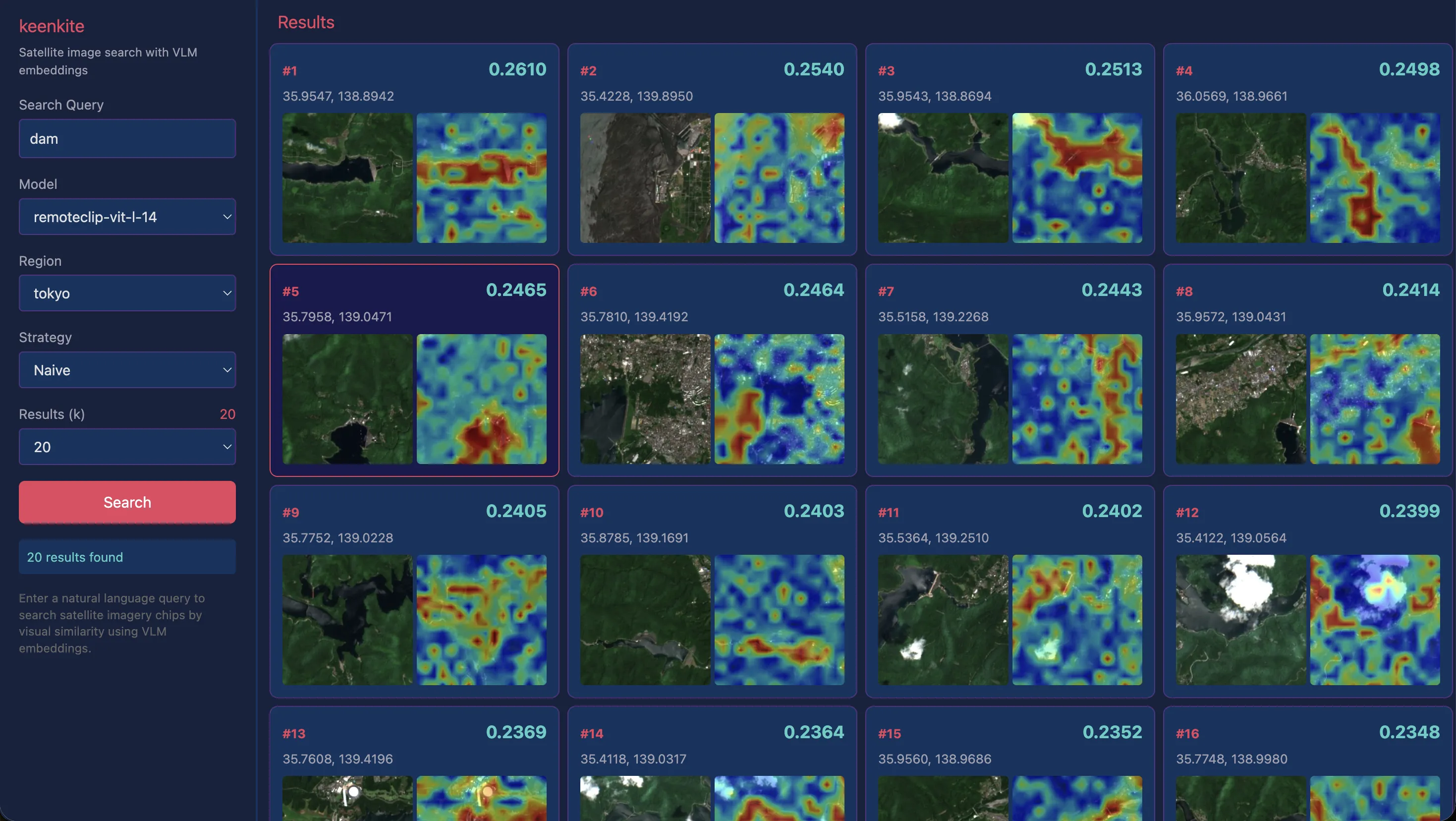
“dam”
For dams, which were somewhat difficult with AlphaEarth Satellite Embeddings, reasonably good results were obtained. However, looking at the heatmaps, high similarity is distributed across the entire lake surface rather than being particularly concentrated on the dam embankment. While we would want the “dam” query to focus on the embankment and immediate downstream area, in practice the model appears to be primarily capturing the lake surface itself.
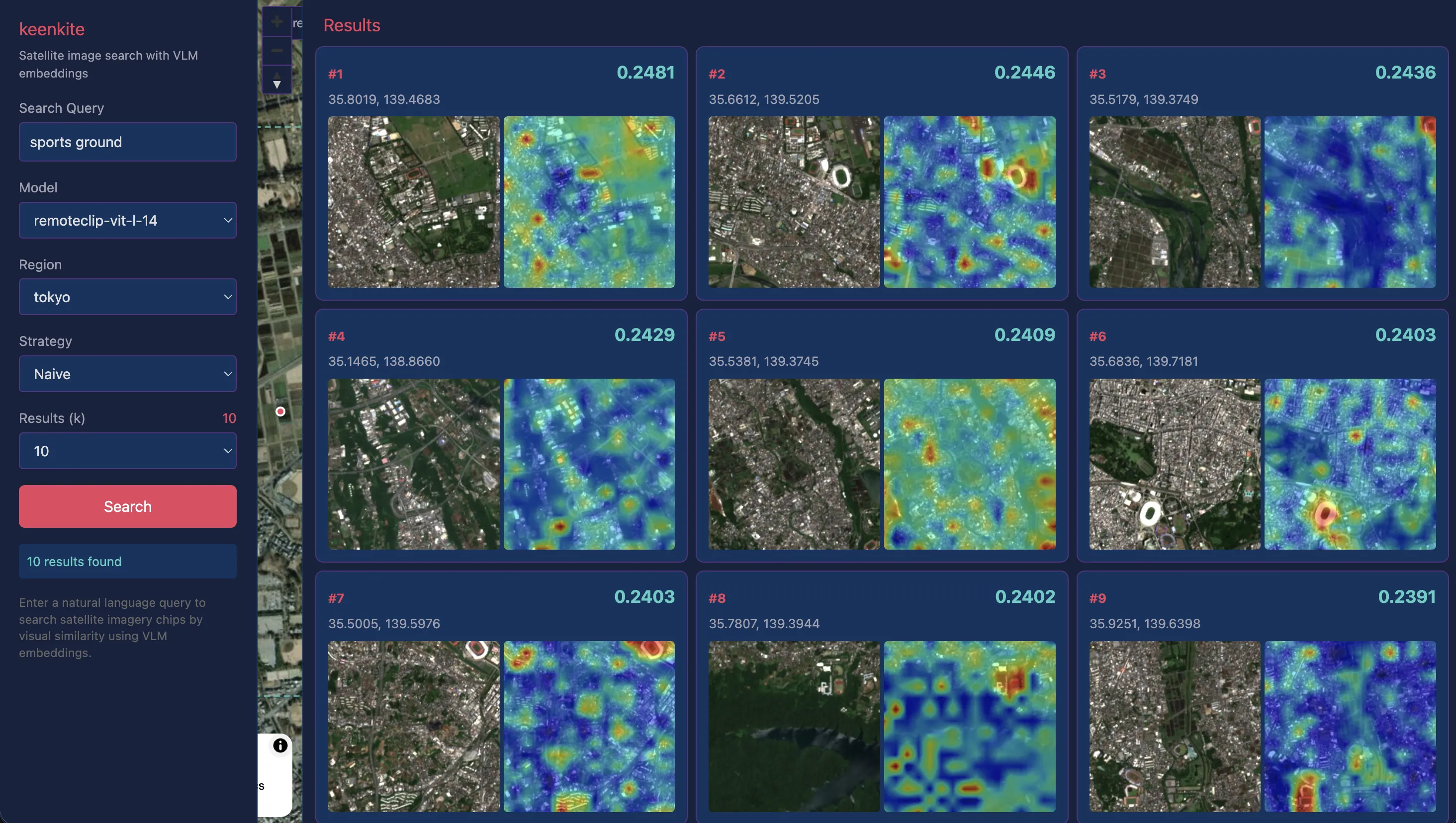
“sports ground”
While previous searches targeted relatively large structures, I also tested smaller sports grounds. Although the search results include some false positives, examples like #2, #3, #6, and #7 show high query similarity on the grounds themselves, indicating that recognition works reasonably well even for smaller structures.
“large station”
Finally, I tested a query with an added condition to see if large train stations in central Tokyo could be detected. Tokyo Station was correctly retrieved, but many other results showed false positives with apartment complexes and large buildings rather than station buildings. Beyond the baseline challenge of recognizing “station” itself, relative modifiers like “large” are difficult for the model to interpret, and information that cannot be captured from satellite imagery alone may also be needed.

Possibilities and Limitations of VLM-based Satellite Image Search
Natural Search Experience Through Language
In the previous AlphaEarth Satellite Embeddings structure search, queries required specifying a “similar location” rectangle on a map. While intuitive, this had the constraint of needing to know an actual example of the target beforehand. Additionally, due to the model’s training data and targets, the similarity metric was not limited to structures, so unintended information like geographic proximity was included.
In contrast, RemoteCLIP’s natural language search allows directly specifying “what you’re looking for” through text. This is a search experience closer to human cognition, with the significant advantage of enabling exploration without knowing an actual example of the target. Furthermore, by using only pure satellite imagery as data, ground structures can be captured more visually.
Complexity and Challenges of Language Understanding
In this experiment, single-concept queries like “airport” and “golf course” yielded relatively good results. On the other hand, cases where slightly adding conditions — such as “large station” or “coastal airport” — failed to produce intended results were notably common in testing.
Let’s consider this behavior in terms of RemoteCLIP’s training data structure. RemoteCLIP’s training data generation method, Box-to-Caption (B2C), generates template-like captions from bounding boxes such as “There are 3 planes in the center of the image,” limited to expressions about scene categories, object enumeration, and coarse positions like whether something is centered.
Additionally, there are structural issues common to all CLIP-based models. CLIP’s text embeddings are known to effectively behave as “bag-of-words,” making it difficult to accurately capture word order and attribute bindings. In the context of satellite imagery, this means it cannot distinguish spatial relationships like “hangars north of the runway” versus “runway north of the hangars.” The ARO (Attribution, Relation and Order) benchmark has reported cases where understanding of attributes, relations, and word order falls below chance level. Furthermore, reports indicate that negation expressions cannot be properly processed (Alhamoud et al., 2025), and text input is limited to 77 tokens, preventing handling of long descriptions (Urbanek et al., 2024), meaning constraints on complex queries are wide-ranging.
In summary, with the current RemoteCLIP, due to constraints from the training data structure and CLIP-based model architecture, practical search is limited to concise single-concept queries, and queries containing complex conditions remain challenging. Solving these issues will require approaches based on semantic understanding of language itself, such as large language models (LLMs), and this is expected to be an active area of research going forward.
Trade-off Between Tile Size and Search Scale
In this experiment, I used tiles of 224×224 pixels at Sentinel-2’s 10m/pixel resolution, meaning approximately 2.24km × 2.24km per tile. This granularity is suitable for km-scale structures like golf courses and airports but is too coarse for individual buildings or road intersections.
On the other hand, reducing tile size enables searching narrower areas but decreases contextual information, making it harder to capture “features of a location including its surroundings” — a trade-off. In the previous AlphaEarth Satellite Embeddings, linear composability of embeddings allowed adding small tile embeddings together to create representations at arbitrary spatial scales. With VLMs, however, the model’s fixed input size (224×224) means the choice of resolution directly determines the search target’s scale. This is a problem that remains difficult to solve even with higher-resolution satellite imagery (0.3m/pixel from commercial satellites).
Conclusion
In this article, I experimented with satellite image search using natural language text through RemoteCLIP. I split Sentinel-2 images into 224×224 pixel tiles, generated embeddings with RemoteCLIP, built an index with Qdrant, and implemented and tested a web application for searching.
While the previous AlphaEarth Satellite Embeddings took a Query-by-Example approach of searching by providing similar location examples, this time I used a Query-by-Text approach. The convenience of being able to explore satellite imagery simply by entering text without preparing labels or annotations is appealing. On the other hand, challenges for practical use became apparent, including handling complex queries and the spatial resolution trade-off.