Agentic Coding時代のデータ分析コンペの環境構築
久しぶりにデータ分析コンペ(atmacup#23)に出場したのを機に、Agentic Coding時代のコンペの環境構築をしました。コンペ自体の成績はイマイチな結果に終わりましたが、個人的にはAgentic Coding時代の手応えを感じたと同時に課題も見えてきました。
この記事では、このコンペで構築した現在の私の実験環境の事例を紹介します。
Agentとの協業理念
まず分析やコーディングの大半をAgentにまかせる上で目指したのは、以下の3点です。
- 計画/実行/評価のサイクルを高速に回すための全体構造化と、Agentが迷いなく実行できるようなコマンド/スキル化
- Agentの意思決定を支えるドキュメント整備
- 共通コンポーネントをなるべく排除し実験間の依存性をなくすことで単体での再現性を確保
Agentというものは現時点では「何でも知っているし何でも出来るけれども、人間が言わないと提案してくれないしやってくれない」存在なので、人間による大まかな方針の提示と意思決定、そして意図した挙動へ導くガードレールが必須です。とにかくAgentが最高速度で突っ走ってくれるサポートをします。それが出来ていないならすべて人間のせいです。
また、人間が見る部分と見ない部分の切り分けをはっきりすることが重要です。人間が見る部分というのは、実験の設計や結果などの抽象的な情報、見ない部分というのは実験コードや設定情報など具体的な情報です。コードを人間が確認するというのは、いわばマイクロマネジメント。そうしたくなる気持ちをぐっと抑えて、必要に応じてAgentに「この実験のパラメータって何?その根拠は?」といった投げかけにとどめて、人間はもう少し全体の流れをコントロールすべきだと感じています。Agentが間違っていたらどうするんだと思われるかもしれませんが、私が手で実装したり目grepで設定ファイルを探し出すよりは正確です。それよりも、実験の方向性は正しいか、考慮漏れはないか、一度に複数の変更を加えて結果の解釈を難しくしていないかなどを気にしたほうがいいという結論に達しました。
ディレクトリ構造
それでは具体的なディレクトリの構造と各要素の詳細を見ていきます。今回のコンペでは、最終的にこのような形に落ち着きました。
competition_name/
├── CLAUDE.md # Agent用設定ファイル
├── .claude/ # Claude Code設定 (command/skill/hookなど)
├── experiment_summary.md # 実験結果一覧・系譜図
├── experiments/ # 実験ディレクトリ
│ └── expXXX/ # 各実験 (XXXは001からインクリメントする)
│ ├── config.yaml # 実験設定
│ ├── run.py # 実行スクリプト
│ ├── result.md # 実験結果の評価ドキュメント
│ └── submission.csv # サブミッションファイル
├── docs/ # ドキュメント
│ ├── official/ # コンペ公式のドキュメント
│ ├── paper/ # 論文 (doclingから出力)
│ └── survey/ # 技術サーベイ (Deep Researchの結果)
├── data/ # データセット
│ ├── raw/ # 配布データ
│ └── processed/ # 前処理済みデータ
├── app/ # 可視化アプリ
│ ├── backend/ # FastAPIによるバックエンド実装
│ └── frontend/ # React/Next.jsによるフロントエンド実装
├── src/ # 共有ユーティリティ (評価関数の実装など)
├── scripts/ # 前処理などの実験非依存のスクリプト
├── studies/ # 調査・検証用コード置き場
└── pyproject.toml # uv設定 (パッケージ管理)
CLAUDE.md, .claude: Claude Code関係
今回のコンペではすべてClaude Codeに依頼する形で分析/実験を行いました。CLAUDE.mdにはコンペ概要と実験構築の方法、コマンドでの実行方法などを記載し、.claude/以下のコマンド/スキルには実験の評価やドキュメント化などの少々複雑なステップを踏む作業を切り出しています。
はじめから完璧にしておく必要はなく、Agentと協業する中で少しでも違和感を感じたらAgent自体に追記してもらうことを繰り返すことで、意図した動作になるように方向修正していけば良いと思います。
experiments/ による実験管理
データ分析コンペではあらゆる試行錯誤を繰り返すので、実験管理と再現性の担保が最も重要です。そこで実験ごとにexpXXXというディレクトリを新規作成し、実験の学習コードやメタ情報、中間ファイル、サブミッションファイルをまるっと含めて完結するようにしています。パラメータを変えて複数の類似実験を行う際は、variantsディレクトリの中で同様の構造を持つ形にしました。
experiments/expXXX/
├── config.yaml # 実験設定
├── run.py # 実行スクリプト
├── result.md # 実験結果の評価ドキュメント
├── features/ # 中間ファイルなど
│ ├── train_features.npy
│ └── test_features.npy
└── variants/
├── expXXX_001/ # Variant 1
│ ├── config.yaml # variant固有設定
│ ├── run.py # 親からコピー
│ ├── predictions/
│ └── submission.csv
├── expXXX_002/ # Variant 2
└── ...
実験設定のconfig.yamlでは、実験に使うパラメータ等に加えて、実験自体の情報も記載しています。この実験がどの実験から派生して、何を意図してつくられたのかという前回実験からの差分を記載しておくことで、実験の立ち位置を明確にしています。これらもすべてAgentに作成してもらい、人間はレビュー時の確認にとどめます。
# config.yamlの一例
experiment:
name: exp003
description: "EigenPlaces model/dim/k grid search"
lineage:
parent: exp001
status: active
diff_summary: "Grid search: model/dim/k combinations"
experiment_summary.md: 実験サマリー
実験が膨大な数になってくるとAgentが読み込むコンテクストも増えてしまうので、各実験が終わるたびにプロジェクトのルートに置いているexperiment_summary.mdにも記載をするようにしています。内容としては、実験間の対応関係であったり、サブミット関連の外部から得られる情報です。
- 実験の系統図
- 各実験の概要、CV評価値、LBスコアなどの一覧表
- 実験から得られた知見(Key Findings)
- Changelog (いつ何をしたかを残す目的)
このドキュメントの冒頭では、実験の系統図をmermaid形式で作成して可視化しています。これによって実験の系統がわかりやすくなり、複数の実験を並行して考えていても現在地を見失うことがありませんでした。
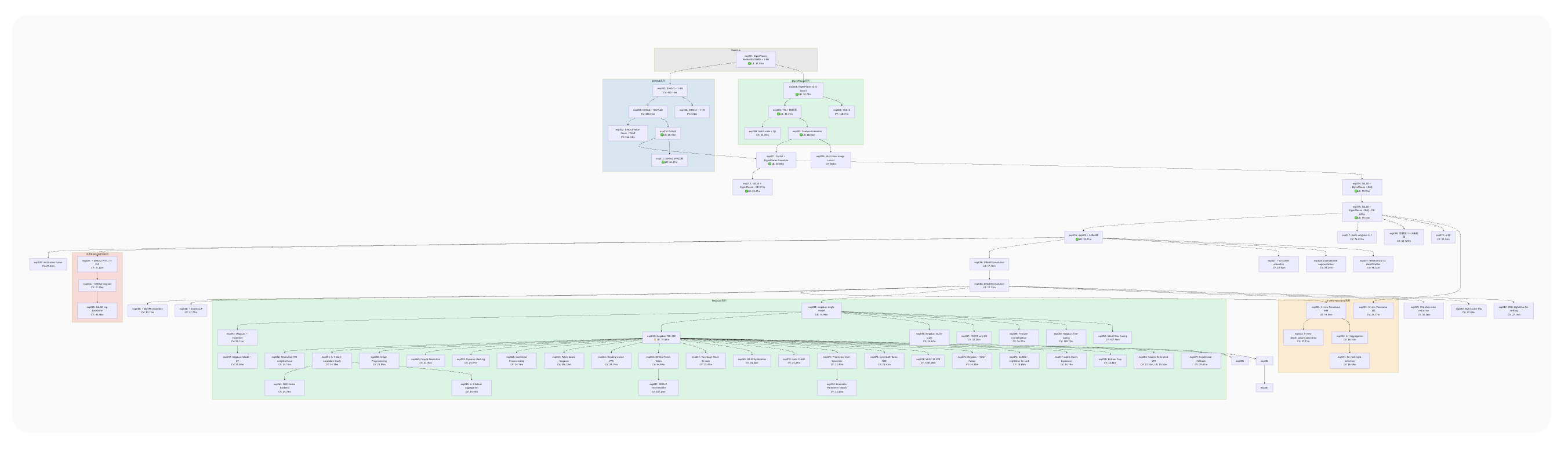
ちなみに中央の大きな緑の部分はMegaLocというモデルの適用以降の試行錯誤の跡です。ここからなかなか精度改善ができなくて、同一実験から大量に関連実験が生えて、ことごとく散っていきました。
docs/: ドキュメント
Agentが実験構築をする上で読み込むドキュメントのディレクトリです。
-
official: ここではコンペのルールや評価方法などの公式が提供している文書を配置しています。評価手法などの重要な情報のみCLAUDE.mdに直に書いておき、提供ファイルの一覧や細かなルールなどは必要に応じてここを参照してもらいました。 -
paper: 論文をAgentが読み込むためにマークダウンで配置します。doclingを使用してCLIから実行できるようにしておき、Agentが勝手にネットから取得するようにしました。 -
survey: ChatGPTやClaudeなどのDeep Research機能で作成したレポートを配置する場所です。これは自動化が出来ていないのでファイル自体は人間が手動でダウンロードして配置し、ファイルのリネームはAgentにやってもらいます。このサーベイのファイル群もかなりの数になってしまうので、コンペに関係のある情報のみをsummary.mdに書き出してもらうようにしてコンテクストの圧縮をしています。
docs/
├── official/ # コンペ公式ドキュメント
│ ├── rule.md # ルール・データ説明
│ ├── evaluation.md # 評価指標の詳細
│ └── *.pdf # 公式スライド
│
├── paper/ # arXiv論文のMarkdown化ファイル
│ ├── README.md # 論文索引
│ └── XXXX.XXXXXvX.md # 論文本文(arXiv ID)
│
└── survey/ # 技術サーベイ (Deep Researchから取得)
├── summary.md # サーベイまとめ
├── 01_vpr_comprehensive.md
├── 02_competition_solutions.md
├── 03_geolocalization_methods.md
├── ...
└── XX_depth_panorama_synthesis.md
app/: 可視化/分析アプリケーション
Agentにあらゆる実装をまかせられるようになり、自分独自の可視化や分析アプリケーションを作るのが容易になりました。Streamlitではページ管理が面倒だったり可視化手法ですぐ限界が来てしまうので、通常のWebアプリケーションのようにFastAPI/Reactのような構成で実装しています。
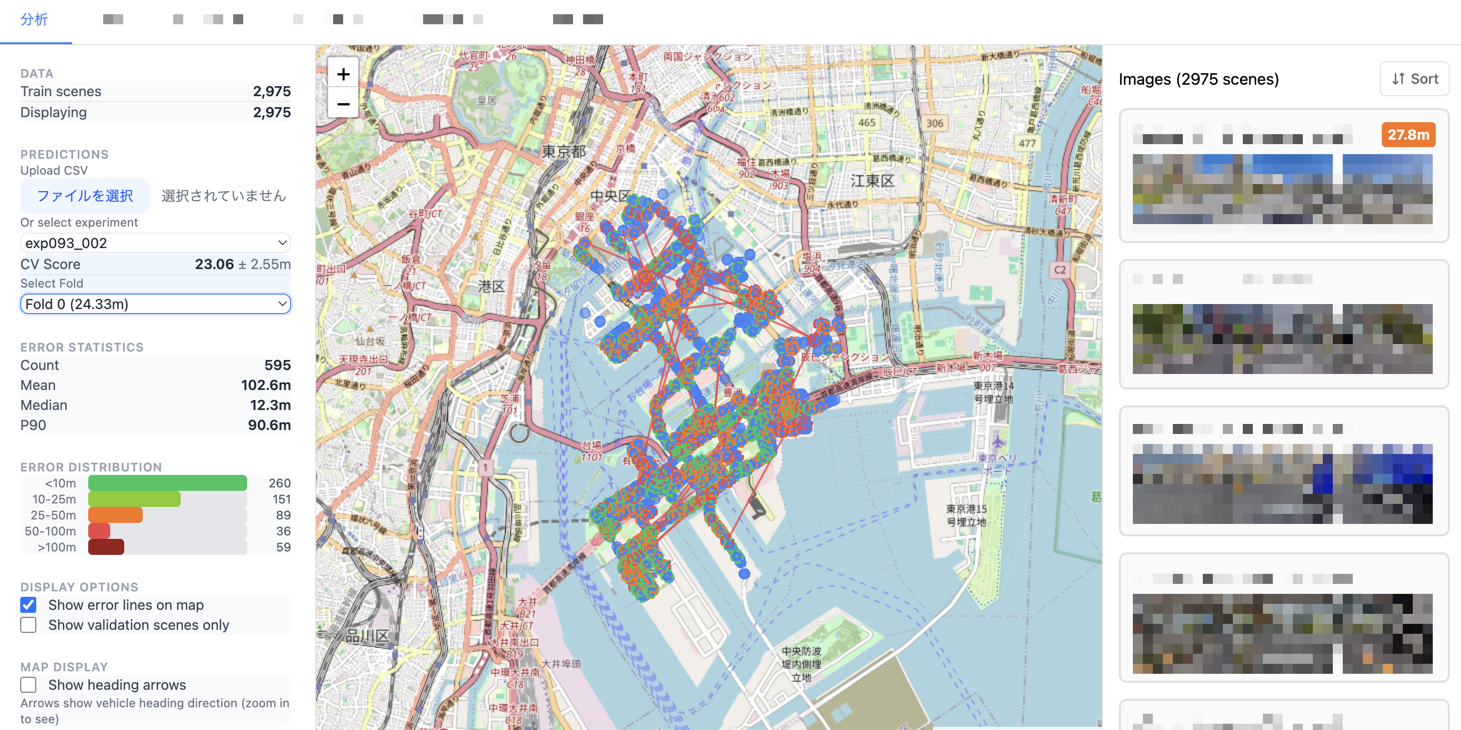
ちなみに、一例ですが今回のコンペではこのような可視化の画面を作りました。
実験ごとのCVの結果の可視化画面
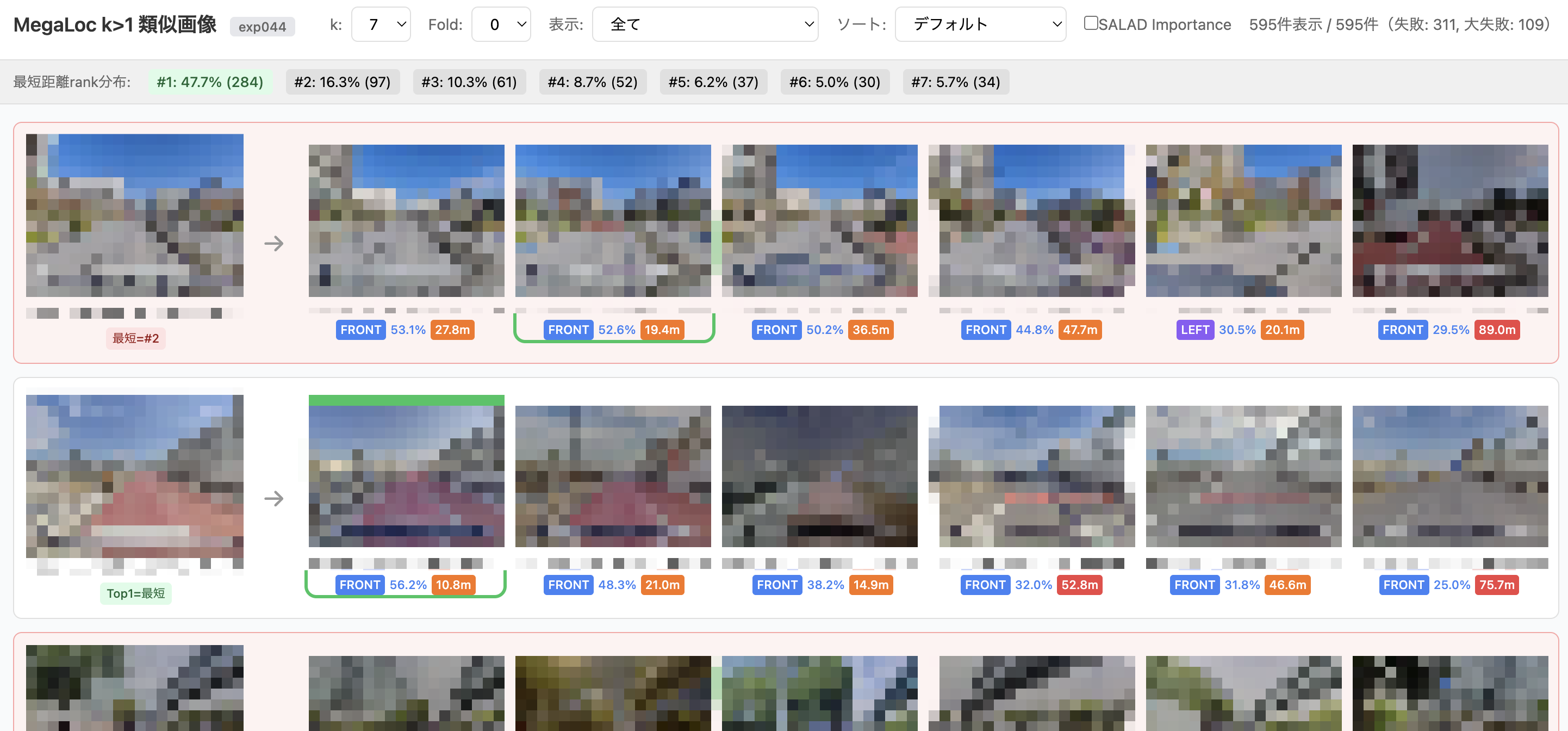
kNN(k>1)の評価用画面
今後の方向性
今回のコンペでは、すべてのコードをAgentに書いてもらい、人間は実験プランを考えて次の方向性を定めるというより高次な意思決定に注力することができました。今まででは考えられないほどのスピードで実験を試すことができるようになった一方で、Agentが出してくる結果の解釈に手間取ったり、そもそもの技術的な理解に時間がかかるなど、人間側のボトルネックもかなり明確になりました。
まだ私自身試せていないこととしては、
- 完全にAgentに任せた実験評価サイクルの実現
- 複数Agentの協業 (Codexやその他LLM)
- チケットによる実験アイデアの管理とAgentによる自動検証
- 人間の理解力補助のための図示 (Nano Banana Proの画像生成など)
があります。
まだまだ手放しで完結できるほどの状態ではありません。より自律的かつ効率的なコンペ攻略を目指すために、人間側がさらに試行錯誤し自身の能力をアップデートしていく必要があると感じています。