衛星画像をテキストで検索する — Vision Language Modelによるアプローチ
目次
概要
前回の記事では、AlphaEarth Satellite Embeddingsを使って「似た構造物を探す」というQuery-by-Example型の検索を試しました。地図上で矩形を選択してそのエリアに類似した場所を近似最近傍探索(ANN)で探すというアプローチのため、「空港を探したい」「ゴルフ場を探したい」といった意図を直接的に表現することはできませんでした。
今回は、自然言語のテキストクエリで衛星画像から直接目的の構造物を検索する仕組みを試してみます。リモートセンシング画像向けにfine-tuningされたVLM(Vision-Language Model)であるRemoteCLIPを使用し、"airport"や"golf course"といったテキストを入力するだけで、それに合致する衛星画像タイルを検索できるようにします。
RemoteCLIPとは
RemoteCLIP(Liu et al., 2024)は、OpenAIのCLIPを約80万組のリモートセンシング画像-テキストペアでfine-tuningしたモデルです。CLIPは画像とテキストを同一のベクトル空間に埋め込むことができるため、衛星画像をタイルに分割してあらかじめembeddingsを生成しておき、検索時にはテキストクエリを同じ空間に埋め込んでANNで類似度検索することで、テキスト→画像の検索が実現できます。
実装
本記事で紹介する実装のソースコードはGitHubで公開しています。
Satellite image natural language search system using VLM embeddings
全体の処理フローは以下のとおりです。インデックスを構築する部分と、自然言語による検索を行う部分の2つに分けられます。
[インデックス構築]
Sentinel-2 (STAC API)からダウンロード
↓
タイル分割
↓
RemoteCLIPによる埋め込み生成
↓
Qdrantでインデックス構築
[自然言語による検索]
テキストクエリ
↓
RemoteCLIPによるテキスト埋め込み
↓
Qdrantで類似検索
↓
結果表示
データソース
衛星画像にはSentinel-2 L2Aを使用しました。Sentinel-2はESA(欧州宇宙機関)が運用する地球観測衛星で、データは誰でも無償で利用できます。L2Aは大気補正済みの地表面反射率プロダクトで、可視光バンドの空間分解能は10mです。RGB 3バンドを取得し、反射率値(uint16)を0-3000の範囲でクリッピングした後に0-255のuint8に変換しています。
今回は関東平野を対象に、4月~6月の春の期間に雲量20%以下の条件で地表の構造物が見える状態の画像を取得しています。
インデックスの構築
シーンの取得とタイル分割
Element84のSTAC APIを通じてSentinel-2のシーンを取得し、ローカルにGeoTIFFとして保存します。その後RemoteCLIPの入力サイズである224×224ピクセルのタイルに分割します。Sentinel-2の解像度が10m/pixelなので、1タイルは約2.24km×2.24kmの地表面に対応します。
タイル分割の際にタイル同士に重なりがないように分割すると、タイルの境界をまたぐ構造物がどちらのタイルでも部分的にしか映らず検索で見逃す可能性があります。そこでストライドをタイルサイズの半分(112ピクセル)に設定し、隣接タイルと50%のオーバーラップを持たせることで、構造物がいずれかのタイルの中心付近に収まるようにしています。
その結果、関東平野のタイル数はストライドなしで788枚、ストライド50%で3,133枚となりました。
埋め込みベクトルの生成
分割されたタイル画像をRemoteCLIPに入力し、embeddingsを生成します。モデルはViT-B/32(512次元)とViT-L/14(768次元)の2つを試しました。推論はGPU(CUDA)上でFP16で行い、バッチサイズ64で処理しています。
ベクトルインデックスの構築
生成されたembeddingsを検索可能にするためのベクトルDBとして、今回はQdrantを使用しました。前回の記事ではFaissを使用しましたが、Faissは純粋なANN検索に特化しておりメタデータフィルタリングやREST APIが組み込まれていません。QdrantはRust製で軽量ながら、ペイロードによるメタデータフィルタリングに加え、バウンディングボックスや半径検索といったネイティブな地理空間フィルタリングをサポートしています。衛星画像検索では「特定の地域内で検索する」といった空間制約が必要になるため、ベクトル類似度検索と空間フィルタリングを単一のクエリで組み合わせられる点が大きなメリットです。今回はローカルファイルストレージモードで使用し、緯度経度・シーンID・リージョンなどをペイロードとして格納しています。

自然言語による検索
自然言語による検索時は、入力されたテキストをRemoteCLIPのテキストエンコーダーでembeddingsに変換し、Qdrant上のタイル画像embeddingsとのコサイン類似度で上位k件を返します。
これらのインターフェイスとして、バックエンドはFastAPIで構築し、フロントエンドはReact + TypeScript + MapLibre GL JSで地図上に検索結果を表示するUIを実装しました。
ClearCLIPによるヒートマップ可視化
検索結果に対して、モデルが画像のどの領域に注目しているかを可視化するためにヒートマップを生成しています。手法にはClearCLIP(Lan et al., ECCV 2024)を採用しました。
ClearCLIPでは、ViTエンコーダーの最終Transformerブロックにおいて残差接続とFFNをスキップし、自己注意の出力のみを取り出すことで、各パッチに対応する局所的な特徴量を抽出します。さらにパッチ全体の平均を差し引くことで共通成分を除去します。こうして得られたパッチ特徴量(ViT-L/14の場合16×16=256パッチ、各768次元)と検索テキストの埋め込みとのコサイン類似度を計算し、空間グリッドにreshapeして元画像にオーバーレイすることでヒートマップを生成しています。
検索の具体例
関東平野の衛星画像に対して、いくつかのテキストクエリで検索を試してみました。
以下のスクリーンショットは、左側に検索クエリおよび利用モデルなど各種条件、中央に地図と検索でヒットした場所をドットで表示、右側には類似度の降順でヒットした場所の衛星画像とその領域内のClearCLIPによるヒートマップを表示しています。
“airport”
空港に関しては良好な結果が得られました。羽田空港をはじめとして、自衛隊や米軍の駐屯地の滑走路も取得できています。
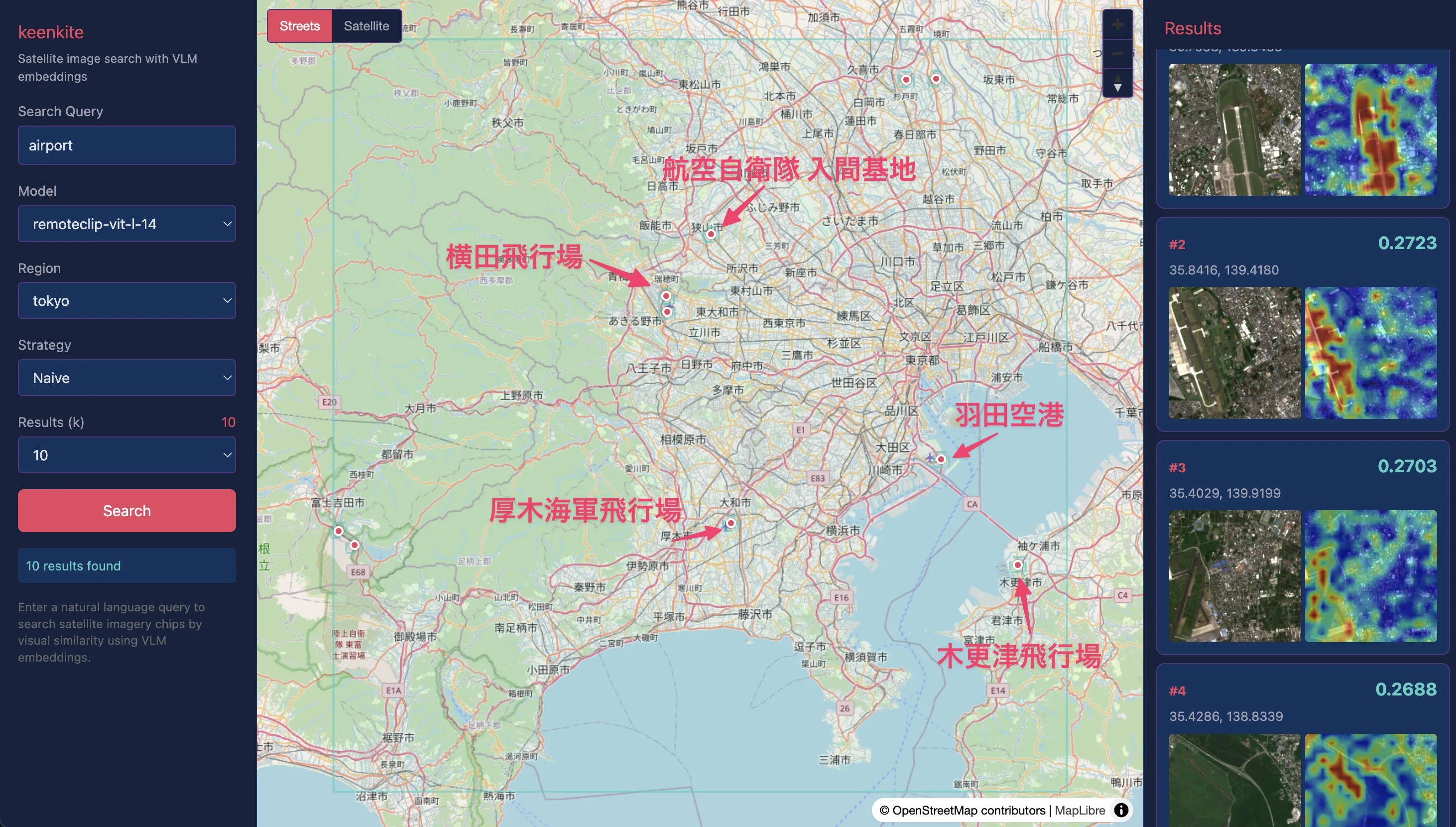
以下のように、ClearCLIPによるヒートマップでも、滑走路部分がクエリと高い類似度を示していることがわかります。山梨県付近の高速道路部分も一部誤検出があることからも、識別の手がかりとしては空港のターミナル部分というよりかは滑走路が主な要素のようです。
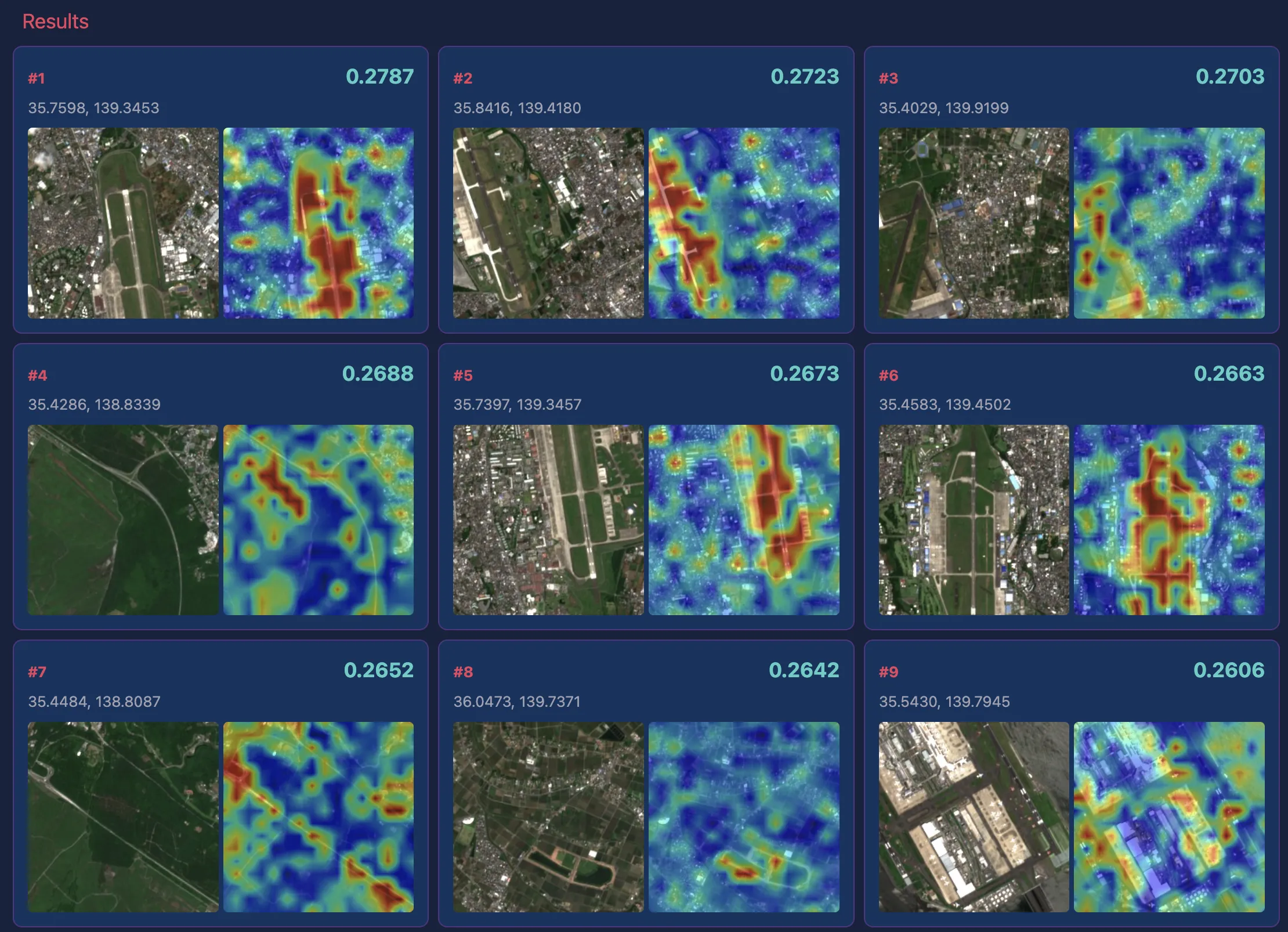
“golf course”
ゴルフ場もほぼすべての例で正確にコースを捉えられていることが衛星画像とヒートマップからわかります。
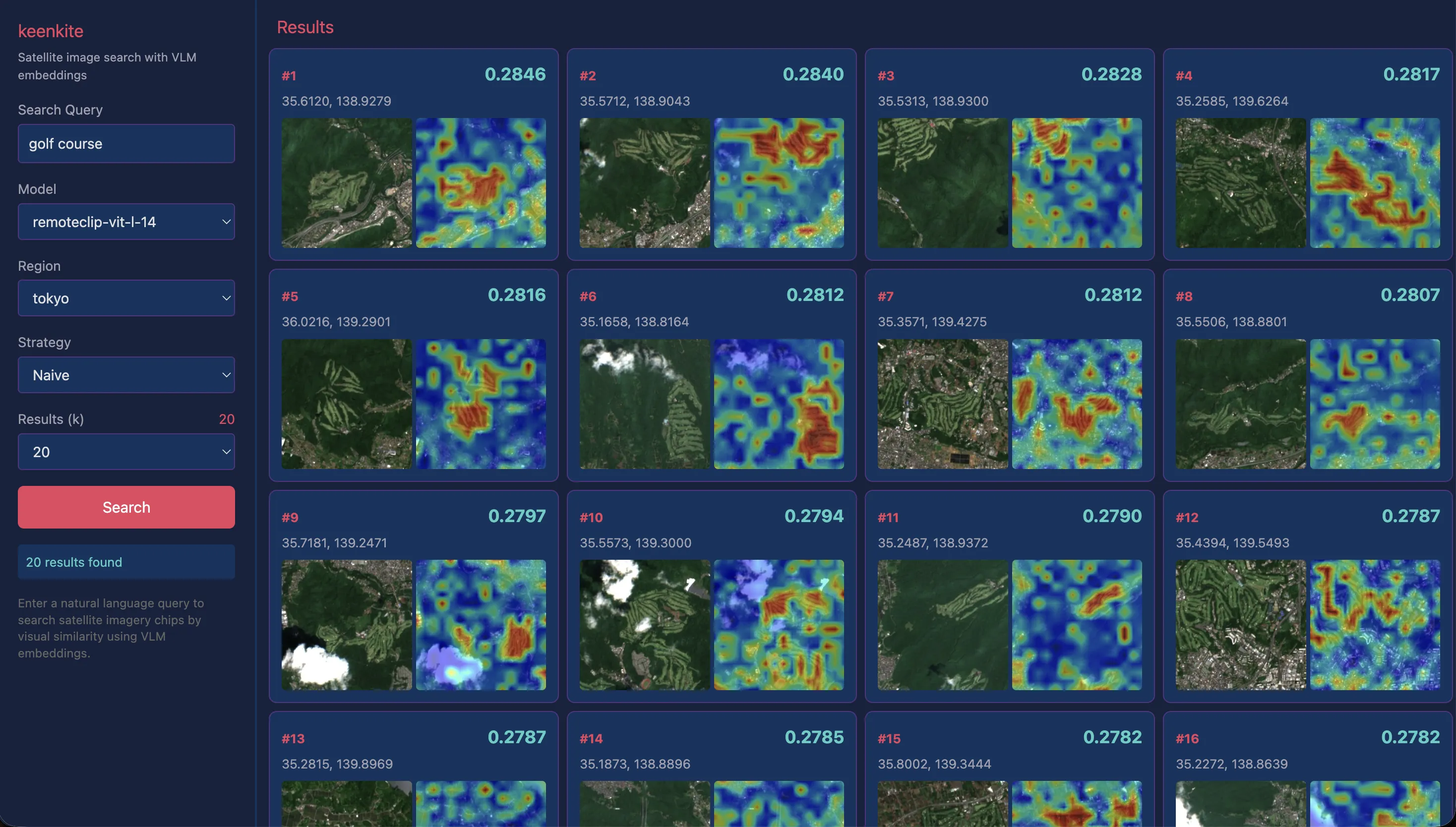
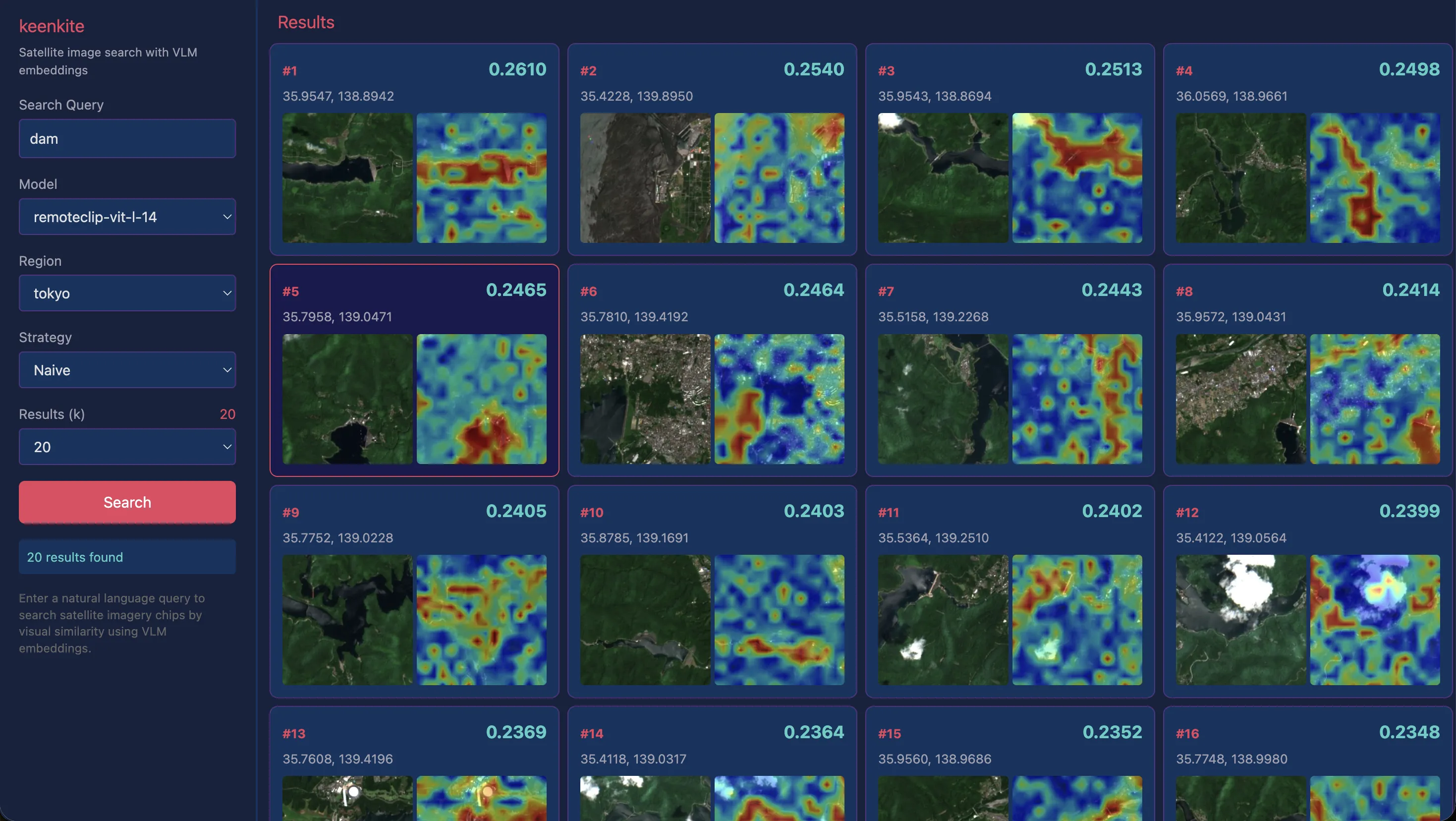
“dam”
AlphaEarth Satellite Embeddingsでは少々困難だったダムの事例においては、一定良い結果が得られています。ただし、ヒートマップを見ると湖面全体に高い類似度が分散しており、ダムの堰堤部分に特に強く反応しているわけではありません。“dam"というクエリに対して堰堤とその直下流域に注目してほしいところですが、実際には湖面そのものを捉えている可能性が高いです。
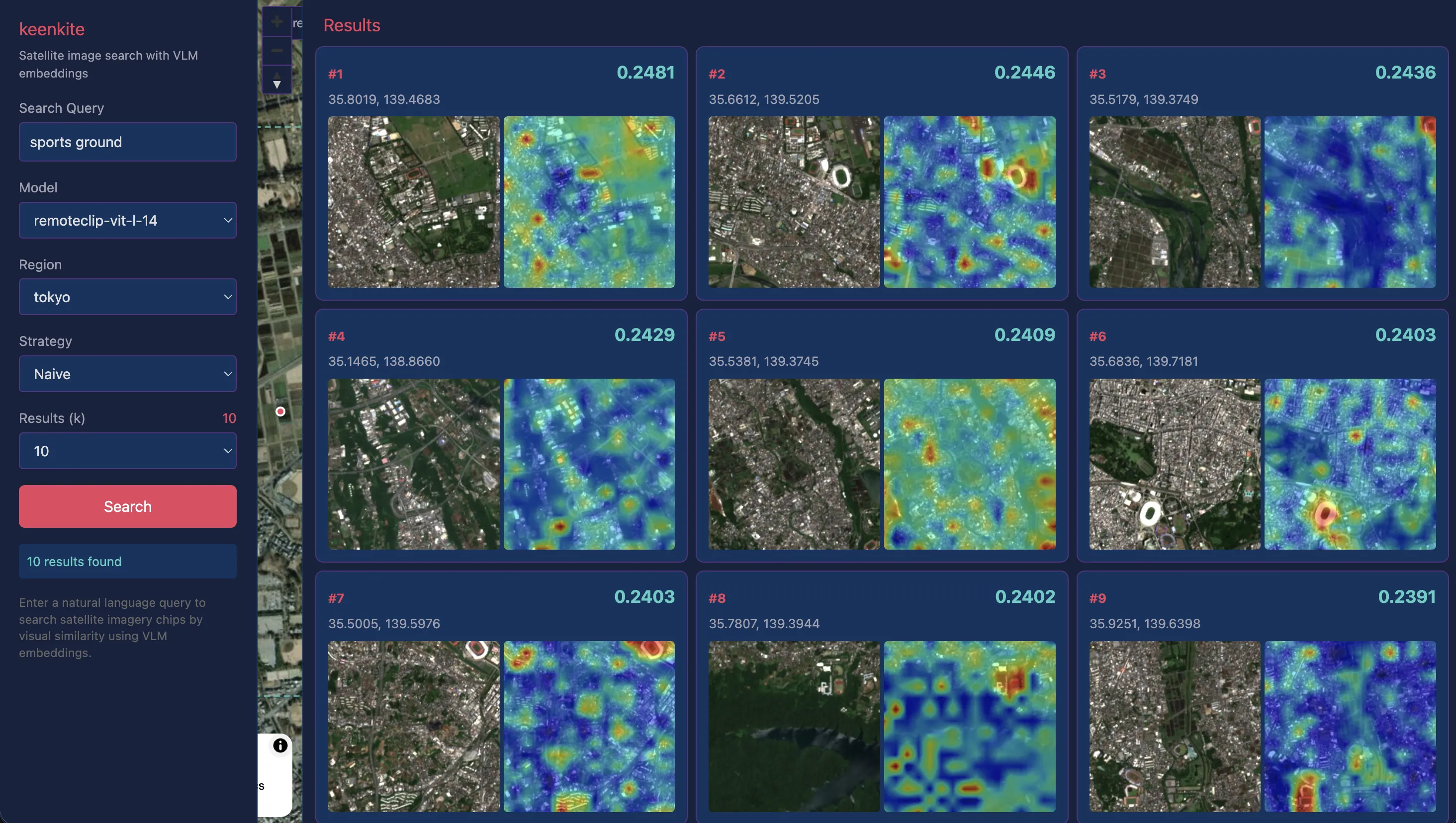
“sports ground”
これまではある程度大きな構造物に対しての検索でしたが、少し小さなスポーツグラウンドに対しても検証してみた結果です。検索精度としては誤検出も含まれていますが、#2,#3,#6,#7などグラウンド自体にクエリと高い類似度を示していることから、一定の小さな構造物でも認識がうまくいっていることがわかります。
“large station”
最後に、少し条件を加えたクエリとして、東京都心の大きな駅を捉えられるかを試してみました。東京駅は正しく取得できましたが、それ以外では駅舎ではなく団地や大型建造物を誤検出している例が多く見られました。そもそも"station"自体の認識精度に課題がある上に"large"のような相対的な修飾語はモデルにとって解釈が難しく、また衛星画像だけでは捉えれない情報も必要と考えられます。

VLMによる衛星画像検索の可能性と限界
言葉による自然な検索体験
前回のAlphaEarth Satellite Embeddingsを使った構造物検索では、クエリとして「似た場所」の矩形を地図上で指定する必要がありました。これは直感的ではあるものの、探したい対象の実例を事前に知っている必要があるという制約があります。また、モデルの学習データ/学習ターゲットの都合上、類似という尺度は構造物に限定されないため、地理的な近さなどの意図しない情報が含まれていました。
一方、RemoteCLIPによる自然言語検索では、テキストで直接「何を探しているか」を指定できます。これは人間の認知により近い検索体験であり、対象の実例を知らなくても探索が可能になるという大きな利点があります。また、純粋な衛星画像のみをデータとして用いることで、より地表の構造物を視覚的に捉えることができます。
言語理解の複雑さとハードル
今回の検証では"airport"や"golf course"のような単一概念のクエリでは比較的良好な結果が得られました。一方、“large station"であったり他には"coastal airport"のように条件を少し加えたものの意図した結果が得られないケースが検証では目立ちました。
この挙動をRemoteCLIPの学習データの構造から考えてみます。RemoteCLIPの学習データ生成手法であるBox-to-Caption(B2C)は、バウンディングボックスから"There are 3 planes in the center of the image"のようなテンプレート的なキャプションを生成するもので、シーンカテゴリや物体の列挙、中心にあるかどうかなど粗い位置程度の表現に留まります。
加えて、CLIP系モデル全般に共通する構造的な問題もあります。CLIPのテキスト埋め込みは実質的に"bag-of-words"として振る舞うことが知られており、語順や属性の結びつきを正確に捉えることが困難です。衛星画像の文脈では、「滑走路の北側に格納庫がある」と「格納庫の北側に滑走路がある」のような空間関係の違いも区別できないことを意味します。ARO(Attribution, Relation and Order)ベンチマークでは、属性・関係・語順の理解がチャンスレベル以下になるケースも報告されています。このほかにも、否定表現を正しく処理できないという報告(Alhamoud et al., 2025)や、テキスト入力が77トークンに制限されるため長い記述を扱えないという指摘(Urbanek et al., 2024)もあり、複合的なクエリに対する制約は多岐にわたります。
まとめると、現状のRemoteCLIPでは学習データの構造やCLIP系モデルのアーキテクチャ上の制約から、実用的に検索できるのは単一概念の簡潔なクエリであり、複合的な条件を含むクエリについては難しいようです。これらを解決するには大規模言語モデル(LLM)のような言語自体の意味理解からのアプローチが必要であり、今後研究が盛んに行われていくと思われます。
タイルサイズが決める検索スケールのトレードオフ
今回はSentinel-2の10m/pixel解像度で224×224ピクセル、つまり約2.24km×2.24kmのタイルを1単位として扱いました。この粒度はゴルフ場や空港のようなkm規模の構造物には適していますが、個々の建物や道路の交差点のような小さな対象には粗すぎます。
一方でタイルサイズを小さくすると、より狭い範囲を検索できるようになりますが、文脈情報が減少するため、「周辺環境を含めた場所の特徴」を捉えにくくなるトレードオフがあります。前回のAlphaEarth Satellite Embeddingsでは、埋め込みの線形合成可能性(linear composability)により、小さなタイルの埋め込みを足し合わせて任意の空間スケールの表現を作ることができました。一方、VLMの場合はモデルの入力サイズ(224×224)が固定されているため、分解能の選択がそのまま検索対象のスケールを決定するという制約があります。これは、より高解像度の衛星画像(商用衛星で0.3m/pixel)を使ったとしても解決が難しい問題です。
まとめ
今回はRemoteCLIPを使って、自然言語テキストによる衛星画像検索を試してみました。Sentinel-2の画像を224×224ピクセルのタイルに分割し、RemoteCLIPを使ってembeddingsを生成、Qdrantでインデックスを構築し、ウェブアプリケーションの形で検索できるよう実装し検証を行いました。
前回のAlphaEarth Satellite EmbeddingsがQuery-by-Exampleという似た場所を例示して探すアプローチだったのに対し、今回はQuery-by-Textというテキストで探すというアプローチです。ラベルやアノテーションを用意する必要がなく、テキストを入力するだけで衛星画像を探索できる手軽さは魅力的です。一方で、複雑なクエリへの対応や空間解像度のトレードオフなど、実用に向けた課題も見えてきました。